Read about how iDialogue AI Assistants are able to chat with thousands of documents or Salesforce records using a technique called "Retrieval Augmented Generation" (or RAG).
Within 5 years, every enterprise IT Architect will require a basic understanding of embeddings and vector spaces as the intermediary language and storage medium for enabling generative AI.
GPT Dreamin' 2024
RAG application in ChatGPT
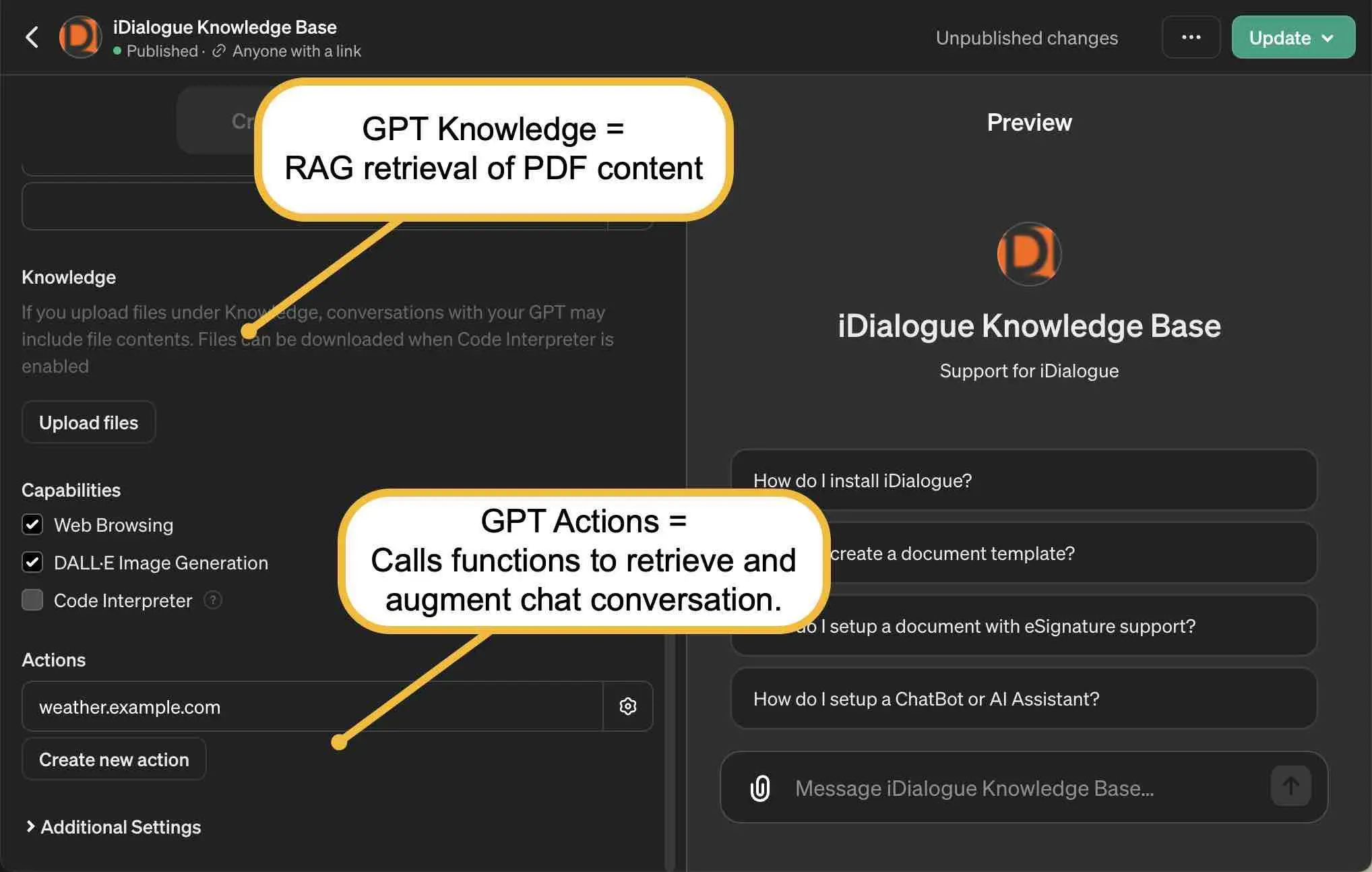
You may have already encountered RAG in ChatGPT.
When you upload a PDF to represent the knowledge base of your chatbot in a GPT setup, behind the scenes, a script is typically run to process it. This script chunks out the PDF, often using one paragraph per chunk as a starting point. These chunks are then inserted into a vector database where embeddings are created. During runtime, when you engage in a conversation, accessing the PDF becomes a type of action. Even without predefined actions in your chatbot, it dynamically determines whether to refer to this PDF or use other retrieval mechanisms.
This process of accessing knowledge sources, like the PDF or other retrieval mechanisms, is a fundamental part of the AI operating system for these actions. These actions can query various databases, such as Shopify or weather APIs, for information.
RAG application in Salesforce - iDialogue
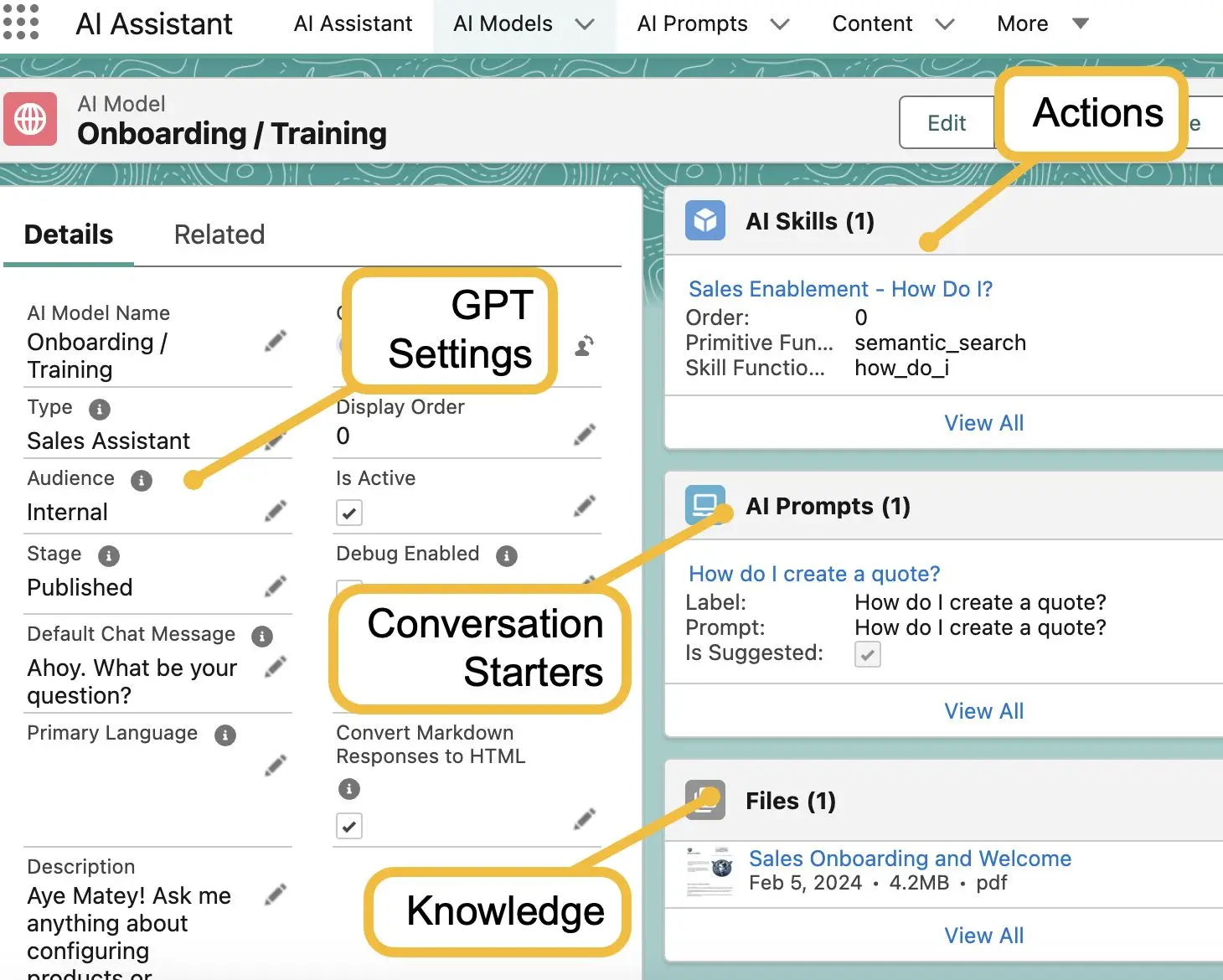
RAG equivalents in SForce
- AI Skills = Actions
- Files = Knowledge
In the context of Salesforce, the benefit of OpenAI's openness is that new features they release can quickly be integrated into platforms like Azure, benefiting products like Salesforce within days.
Anytime ChatGPT gets a new feature, so does Azure, Bing, API apps. Getting these features inside Salesforce is possible through AI-as-a-Service.
Salesforce has developed its own abstraction layer for handling these actions. Instead of actions, they use AI skills, and instead of conversation starters, they refer to them as prompts. Files are managed using related lists of files within Salesforce for knowledge management, and the foundational settings are typically organized into what they term an AI model. This abstraction allows for seamless integration and management of AI capabilities within the Salesforce ecosystem.
.webp)
This is an example of an iDialogue AI Assistant model with RAG Skills such as Semantic Search.
After the user initiates the AI Assistant, it goes through intent moderation, and the function router now has access to a new capability called a vector database. This database can hold various types of data, not just text. For instance, it can handle video and audio vectorization, converting data into a format that's compatible with vector operations optimized for execution on GPUs. Essentially, it has been introduced to a new database, which acts as a cache for Salesforce data, files, enterprise resources, etc.
During runtime, the function determines to fetch additional pieces of text, usually two or three, to add to the conversation stack. The process involves augmentation, where AI Assistant enhances the user request and pass it to the LLM (Large Language Model), and then generative, where it returns the augmented response to the user. In this setup, there are different models available, including the vanilla model, the transactional model, and a more advanced multi-dimensional model capable of referencing the vector database.
Despite the complexity, the model still retains access to the case flow. This means that commands such as troubleshooting, resolving, and updating cases can be executed seamlessly.

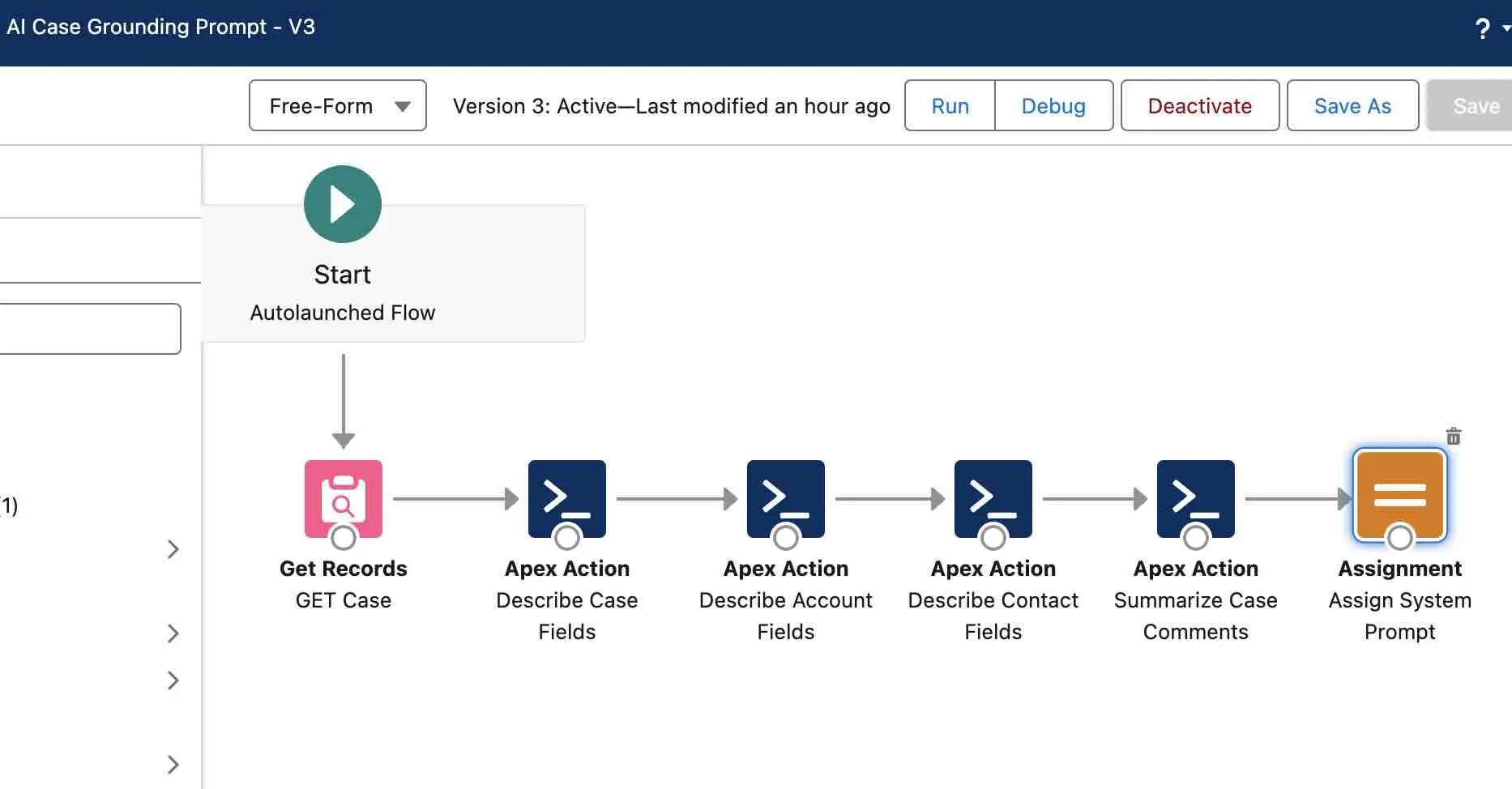
This is the transcript of the chat above.
If we break down the transcript, we can see that when a skill is invoked, along with an action, it triggers the retrieval mechanism. This mechanism involves querying the vector database. There's a step in between retrieval and augmentation where the user prompt is converted. It's important to note that there's a latency involved in this conversion process. Following this, the response from the vector database is augmented with the top-end results, typically two or three, and the outcome is generated.
Now, let's examine the model. We've established a baseline temperature, keeping it very low. In these models, we aim to avoid excessive creativity in the vector database. Our goal is to maintain a literal interpretation of the user input whenever possible.
To achieve this, we call a Flow on initialization to ground it. Additionally, we've implemented several skills. These skills enable the model to branch out in search of knowledge and to update case resolutions.
Tradeoffs: Inline Context vs RAG
In AI development, choosing between inline context and RAG involves tradeoffs.
Inline context offers quick implementation but leads to slower runtime and higher costs. On the other hand, RAG demands extra development effort but enables faster function routing and lower token costs.
Developers must weigh these factors based on project needs and priorities.
Inline context
- Path of least resistance
- Faster development
- Ideal for loading many related files
- Slower runtime (Wirth’s Law)
- Costs more $$$ (charged per tokens)
RAG
- Extra dev effort to define actions / Skills
- Faster function routing and smaller token payloads (vector search time exempt)
- Requires vectorized embeddings
- Cheaper $ (fewer tokens)
Salesforce-Specific Retrieval Techniques
AI-Generated SOQL Query
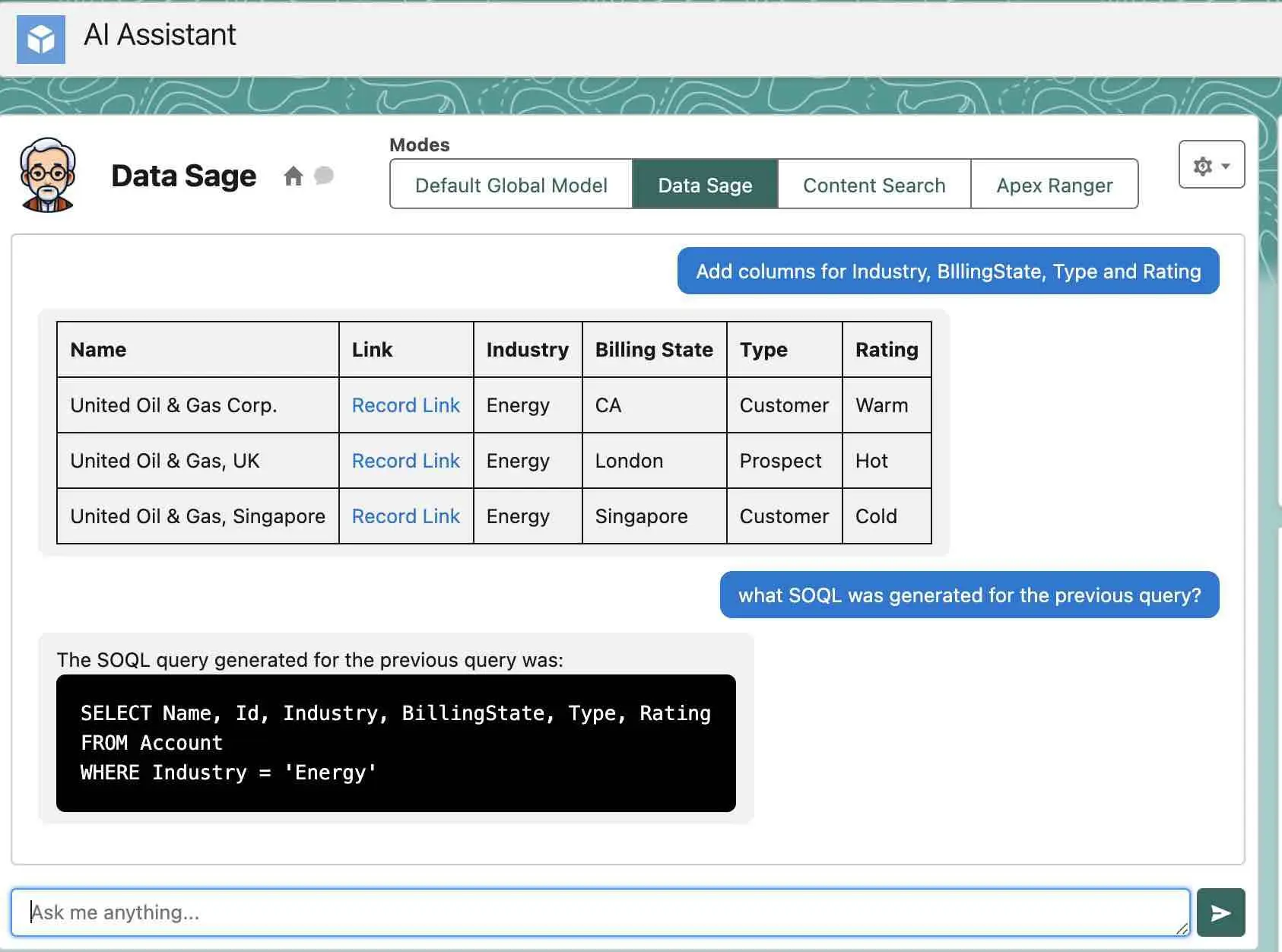
This model understands what an Account is in the Field. So, we can ask it questions like, "Which accounts are in the energy industry?" This is an example of Progressive retrieval - with generalist AI, without grounding.
Semantic Search of File Libraries
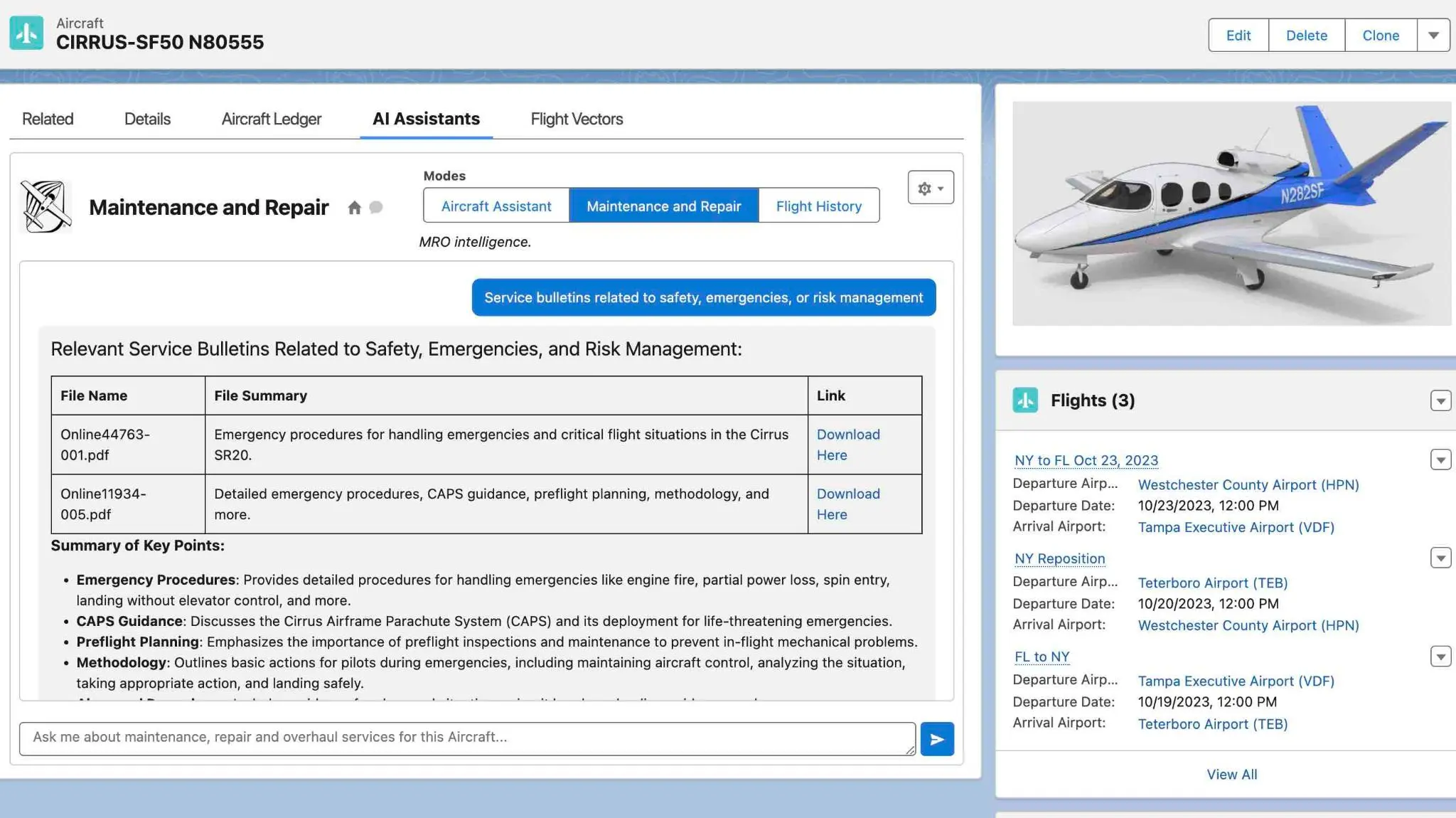
This model received several files, some of which are quite large, around 3 pages each. Loading such documents can take some time, so it's not practical to include entire 300+ page documents in the chatbot's initialization. Instead, we can represent this information in diagrams and store it in a vector database. During runtime, the chatbot can then determine which documents contain paragraphs relevant to the user's intent.
Sales Enablement
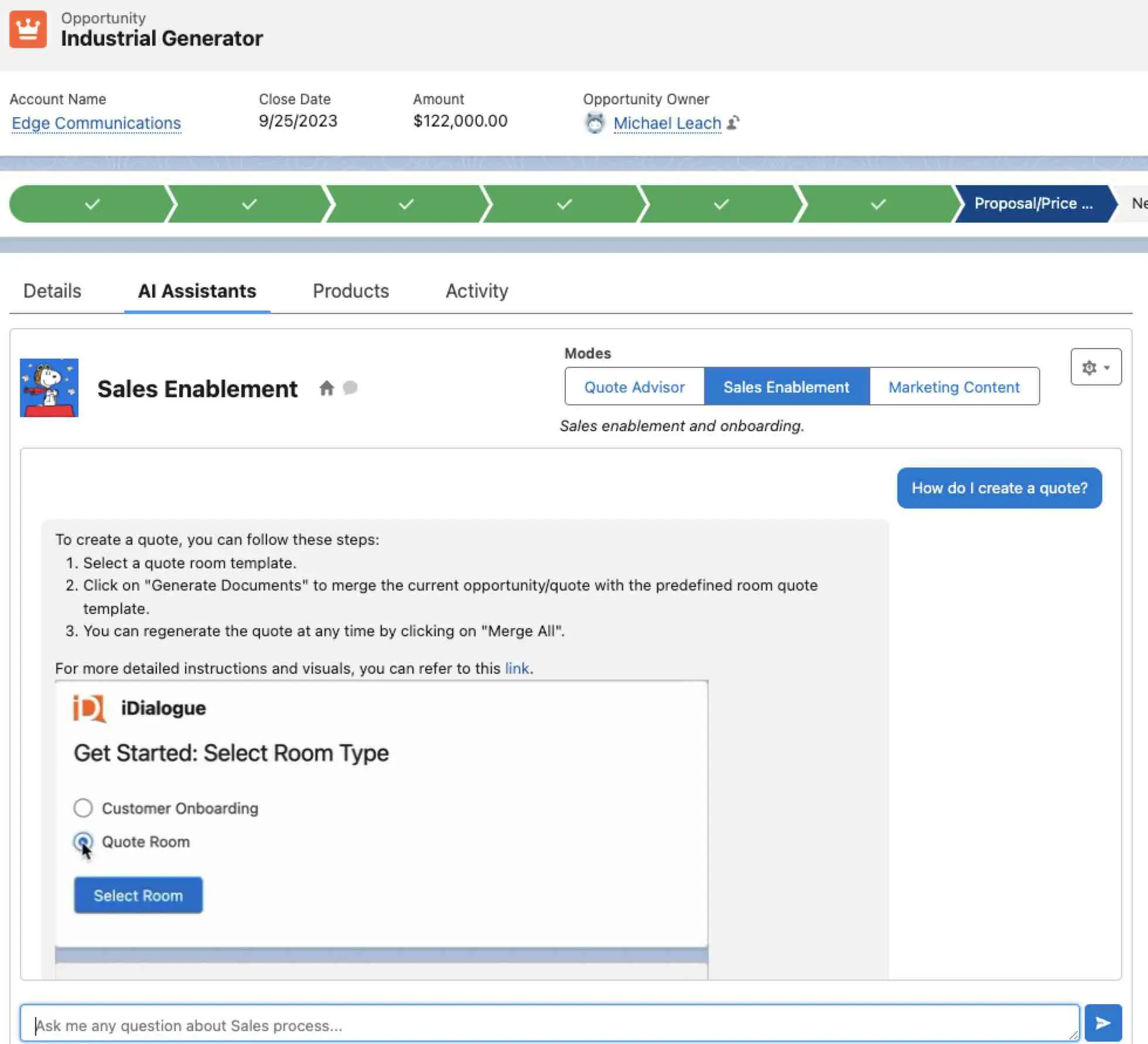
The model is aware of various capabilities, such as guiding users through specific actions, like generating documents. For instance, if a user asks how to create a quote, it might suggest navigating to the upper right-hand corner, clicking on "Generate Documents," and following the prompts.
Sometimes users might throw unexpected questions, like "How can I be notified when a customer views my quote?" In such cases, the system leverages a vector database containing pre-built FAQs, guiding the user accordingly. For example, it might suggest checking the activities tab to see if the customer has opened the email or viewed the quote.
The system manages FAQs through a custom object, which can be any object with a rich text editor. These FAQs are enriched with metadata keywords to facilitate matching in the vector database. When a user asks a question, the system matches it with the most probable answers in the vector database, ensuring the best possible response.
Real-World, Customer Use Cases
Aviation
- Aircraft registration and compliance.
- Flight quote chat bot
- Pilot fatigue management
Legal
- Lease agreement review
- Contract analysis. Search, review, extract key points
- NDA generation
Healthcare
- Prescriptions generation
- Potential drug interaction analysis
- Shipping notifications
Tech
- Sales enablement / online support
- Quote configuration and approvals
Nonprofits
- Volunteer onboarding
- Donor financials and receipts